Background
Millisecond timing error means that your experiment is not working as you intended and that your results might be invalid.- Are you always carrying out the experiments you assume you are?
- Are you aware of millisecond timing error in your own experiments?
- Are you confident you can replicate experiments using
different hardware and software in another lab?




Are you putting your reputation at risk?
We can help
If you wish to discuss how any of our products could help you improve your research feel free to email us. Alternatively contact us by mail, phone or fax.What do I need to know about millisecond timing accuracy
 If
you are a psychologist, neuroscientist or vision researcher who
uses a computer to run experiments, and report timing accuracy in
units of a millisecond, then it's likely your timings are wrong!
This can lead to replication failure, spurious results and
questionable conclusions. Timing error can affect your work even
when you use an experiment generator like E-Prime, SuperLab,
Inquisit, Presentation, Paradigm, OpenSesame or PsychoPy etc.
If
you are a psychologist, neuroscientist or vision researcher who
uses a computer to run experiments, and report timing accuracy in
units of a millisecond, then it's likely your timings are wrong!
This can lead to replication failure, spurious results and
questionable conclusions. Timing error can affect your work even
when you use an experiment generator like E-Prime, SuperLab,
Inquisit, Presentation, Paradigm, OpenSesame or PsychoPy etc.Our product's sole aim is to help you improve the quality of your research prior to publication. The Black Box ToolKit v3 for example helps you check your own millisecond timing accuracy in terms of stimulus presentation accuracy; stimulus synchronization accuracy; and response time accuracy and then tune your experiment to deliver better stimulus and response timing. Whereas the mBBTK (event marking version) helps you independently TTL event mark or produce TTL triggers to send to other equipment. Our range of response pads and other devices help you ensure that your response timing is millisecond accurate and consistent.
A summary of what types of millisecond timing error likely to affect your computer-based experiment is shown below:
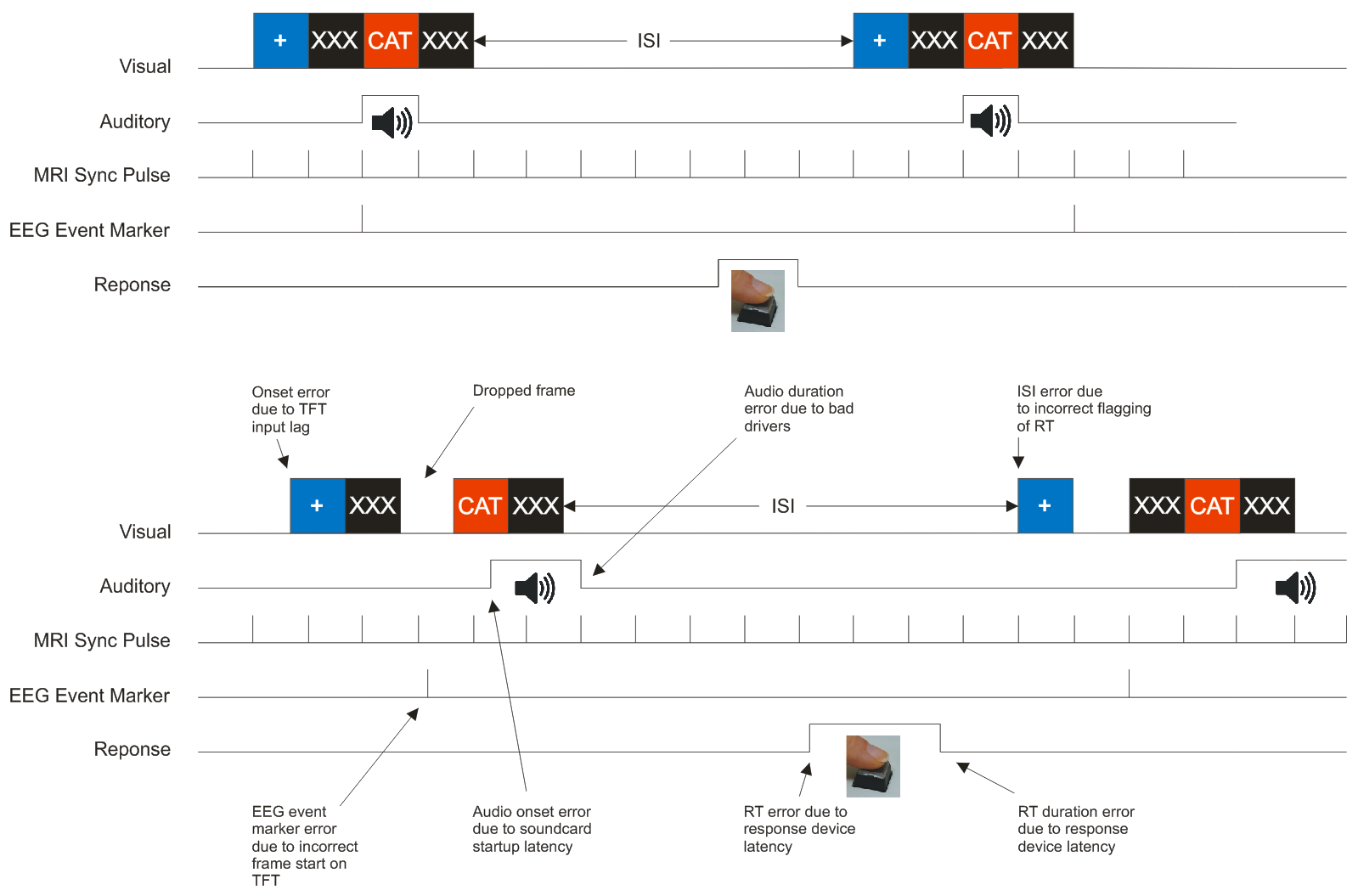
Idealized experiment shown top, what may happen in reality on your own equipment bottom (click to enlarge)Put simply, if you are using a computer to run experiments and report timing measures in units of a millisecond then it's likely that your presentation and response timings are wrong! Modern computers and operating systems, whilst running much faster, are not designed to offer the user millisecond accuracy. As a result you may not have conducted the experiment you thought you had!
Hardware is designed to be as cheap as possible to mass produce and to appeal to the widest market. Whilst multitasking operating systems are designed to offer a smooth user experience and look attractive. No doubt you'll have noticed that your new computer and operating system doesn't seem to run the latest version of your word processor any faster than your old system!
Don't commercial experiment generator packages solve all my problems?
Unfortunately using a commercial experiment generator such as, E-Prime, SuperLab, Inquisit and the like will not guarantee you accurate timing as they are designed to run on commodity hardware and operating systems. They all quote millisecond precision, but logically, "millisecond precision" refers to the timing units the software reports in and should not be confused with "millisecond accuracy", i.e. do events occur in the real world with millisecond accuracy.If you write your own software you will remain just as uncertain as to its timing accuracy. You should also be wary of in-built time audit measures as they can lead to a false sense of security as they are derived by the software itself. For example, if you swap a monitor it is impossible for the software to know anything about a TFT panels timing characteristics, or for that matter about a response device, soundcard or other device you are working with.
It is also impossible to find out which experiment generator offers the most accurate presentation and response timing using generic benchmarks. Often such benchmarks have been conducted using devices such as our BBTK v3, or homemade response hardware, and the experiment generator scripts tuned to give consistent results. The fatal flaw in such an approach is that the authors have tuned the experiment generator to give good results on their own hardware within a very simple script. If you think about it for a moment what this actually shows is that you should be checking and tuning your own experiment on your own hardware with a BBTK v3 to give better results. Results from generic benchmarks cannot possibly apply to your own hardware and experiment as they will be markedly different.
